
Let's face it: manually running scripts and tasks is tedious and error-prone. If you're dealing with Extract, Transform, Load (ETL) pipelines, automating these processes becomes essential for data consistency and timely delivery. This tutorial will guide you through automating your ETL pipelines using cron jobs, freeing you from the burden of manual execution and ensuring your data flows smoothly.
Cron jobs are your trusty sidekick for scheduling tasks on Linux-based systems. They're simple to set up and incredibly powerful for automating repetitive processes like ETL. By the end of this tutorial, you'll be able to confidently schedule and manage your ETL pipelines with cron, leading to more reliable and efficient data processing.
Here's a quick tip to get you started: open your terminal and type `crontab -l`. This command lists any existing cron jobs configured for your user. If it's empty, you're ready to begin!
Key Takeaway: You will learn how to automate ETL processes using cron jobs, ensuring consistent data processing and reducing manual intervention. This includes setting up basic cron schedules, implementing locking mechanisms, and managing logs for robust and reliable pipeline execution.
Prerequisites
Before we dive into the tutorial, let's ensure you have the necessary tools and permissions: A Linux-based system: This tutorial assumes you're working on a Linux distribution like Ubuntu, Debian, Cent OS, or similar. Cron daemon installed and running: Most Linux distributions have cron installed by default. You can check its status with `sudo systemctl status cron`. If it's not running, start it with `sudo systemctl start cron` and enable it to start on boot with `sudo systemctl enable cron`. Basic command-line knowledge: Familiarity with navigating the file system, editing files, and executing commands in the terminal is essential. Text editor: You'll need a text editor like `nano`, `vim`, or `emacs` to create and modify cron job files. Scripting language (Bash or Python): This tutorial uses bash for demonstration purposes. Python is also a popular choice for ETL scripting. Ensure you have either bash or python installed on your system. Permissions: You need to have permissions to read and write to the crontab file for your user. Optional ETL packages:If you're using Python, you might need libraries like pandas, requests, etc. These can be installed using `pip install pandas requests`.
Overview of the Approach
The core idea is to schedule your ETL script to run automatically at specified intervals using cron. This script will handle the entire ETL process: extracting data from a source, transforming it as needed, and loading it into a destination (database, data warehouse, etc.).
The workflow looks like this:
1.Create an ETL script: This script contains the logic for extracting, transforming, and loading your data.
2.Edit the crontab: Use the `crontab -e` command to open the crontab file in a text editor.
3.Add a cron job entry: Define the schedule and the command to execute your ETL script.
4.Save the crontab: Save the changes to the crontab file. Cron will automatically start scheduling the job based on your defined schedule.
5.Monitor the logs: Review the cron logs to confirm the script is running as expected and to identify any errors.
Step-by-Step Tutorial
Let's walk through two examples: a simple end-to-end ETL task and a more advanced setup with locking and environment variables.
Example 1: Simple ETL Script and Cron Job
In this example, we'll create a simple bash script that echoes the current date and time to a log file and then schedule it to run every minute using cron.
1.Create the ETL script:
```bash
#!/bin/bash
# Script to log the current date and time
DATE=$(date)
echo "Running ETL at: $DATE" >> /tmp/etl.log
```
Save this script as `/home/ubuntu/etl_script.sh`. Make it executable using `chmod +x /home/ubuntu/etl_script.sh`.
2.Edit the crontab:
Open the crontab file using:
```bash
crontab -e
```
This will open the crontab file in your default text editor. If it's your first time, you might be prompted to choose an editor. Select your preferred editor.
3.Add the cron job entry:
Add the following line to the crontab file:
```text
/home/ubuntu/etl_script.sh
```
Save the crontab file.
4.Verify the cron job:
Wait a minute or two, then check the contents of the log file:
```bash
cat /tmp/etl.log
```
You should see entries with the current date and time, indicating that the cron job is running successfully.
Explanation
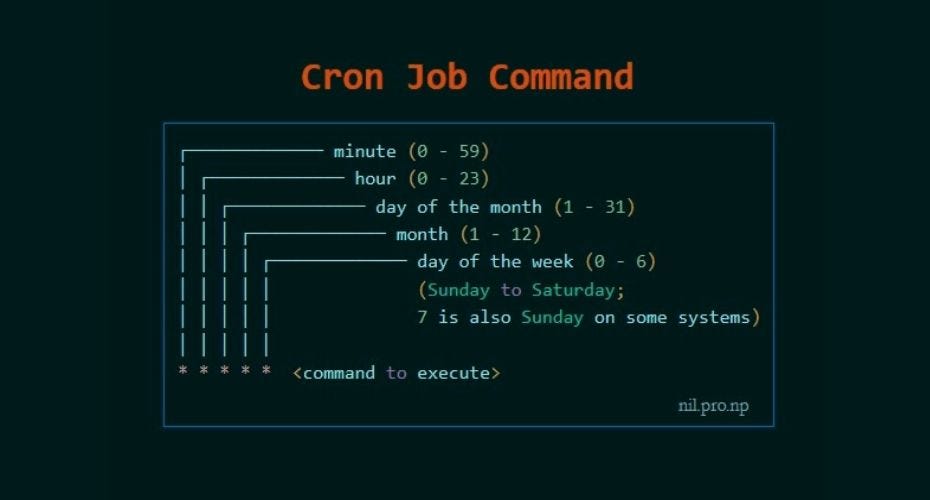
`#!/bin/bash`: This shebang line specifies that the script should be executed using bash. `DATE=$(date)`: This line captures the current date and time using the `date` command and assigns it to the variable `DATE`. `echo "Running ETL at: $DATE" >> /tmp/etl.log`: This line writes the message "Running ETL at: " followed by the current date and time to the `/tmp/etl.log` file. The `>>` operator appends to the file, creating it if it doesn't exist. ``:This is the cron schedule. Each `*` represents a different time unit (minute, hour, day of the month, month, day of the week). In this case, `` means the script will run every minute. `/home/ubuntu/etl_script.sh`:This is the absolute path to the ETL script that should be executed.
Output
After waiting one minute and running the `cat` command, you'll see something like this in the log file:
```text
Running ETL at: Tue Oct 24 14:30:00 UTC 2023
```
Example 2: Advanced ETL Script with Locking, Logging, and Environment Variables
This example demonstrates a more robust setup, including locking to prevent overlapping job executions, using environment variables for configuration, and comprehensive logging.
1.Create the ETL script:
```bash
#!/bin/bash
# ETL script with locking, logging, and environment variables
# Load environment variables from .env file
if [ -f /home/ubuntu/.env ]; then
export $(cat /home/ubuntu/.env | xargs)
fi
# Lock file to prevent concurrent executions
LOCK_FILE="/tmp/etl.lock"
# Logging function
log() {
echo "$(date '+%Y-%m-%d %H:%M:%S') - $1" >> "$LOG_FILE"
}
# Check if lock file exists
if [ -f "$LOCK_FILE" ]; then
log "Another instance is already running. Exiting."
exit 1
fi
# Create lock file
touch "$LOCK_FILE"
# Define Logfile, Default if Env Variable not set
LOG_FILE=${LOG_FILE:-"/tmp/etl.log"}
log "Starting ETL process..."
# Your ETL logic here (replace with actual ETL operations)
sleep 5 # Simulate ETL work
log "ETL process completed successfully."
# Remove lock file
rm "$LOCK_FILE"
exit 0
```
Save this script as `/home/ubuntu/etl_script_advanced.sh`. Make it executable using `chmod +x /home/ubuntu/etl_script_advanced.sh`.
2.Create the environment file:
Create a file named `.env` in your home directory (`/home/ubuntu/.env`) with the following content:
```text
LOG_FILE="/var/log/my_etl.log"
```
This sets the `LOG_FILE` environment variable, which will be used by the ETL script. Adjust permissions on the file to restrict access: `chmod 600 /home/ubuntu/.env`.
3.Edit the crontab:
Open the crontab file using `crontab -e`.
4.Add the cron job entry:
Add the following line to the crontab file:
```text
/5 /home/ubuntu/etl_script_advanced.sh
```
This will run the script every 5 minutes.
5.Verify the cron job:
Wait 5 minutes, then check the contents of the log file:
```bash
cat /var/log/my_etl.log
```
You should see entries indicating that the ETL process started and completed successfully.
Explanation
`if [ -f /home/ubuntu/.env ]; then export $(cat /home/ubuntu/.env | xargs); fi`: This block checks if the `.env` file exists and, if so, loads the environment variables defined within it using `cat` and `xargs`. `LOCK_FILE="/tmp/etl.lock"`: This defines the path to the lock file, which will be used to prevent concurrent executions of the script. `log() { ... }`: This defines a function called `log` that writes a timestamped message to the log file specified by the `LOG_FILE` environment variable. `if [ -f "$LOCK_FILE" ]; then ... fi`: This checks if the lock file already exists. If it does, it means another instance of the script is already running, so the script logs a message and exits. `touch "$LOCK_FILE"`: This creates the lock file, indicating that the script is now running. `LOG_FILE=${LOG_FILE:-"/tmp/etl.log"}`: sets a default value for the LOG_FILE env var if it is not already set. `rm "$LOCK_FILE"`: This removes the lock file when the script finishes, allowing subsequent executions. `exit 0`: This exits the script with a success code.
Output
After waiting 5 minutes and running the `cat` command, you'll see something like this in the log file:
```text
2023-10-24 14:35:00 - Starting ETL process...
2023-10-24 14:35:05 - ETL process completed successfully.
```
Use-Case Scenario
Imagine you have a system that generates daily sales data. You need to extract this data, transform it to fit your reporting schema (e.g., calculating totals, applying currency conversions), and load it into your data warehouse for analysis. Using cron to automate this ETL pipeline ensures that the data warehouse is always up-to-date with the latest sales figures, without requiring manual intervention. This allows business analysts to access the most current information for informed decision-making.
Real-world mini-story
A Dev Ops engineer named Sarah worked for an e-commerce company. They had a daily task of backing up the database to an offsite location. Initially, Sarah performed this manually, which was time-consuming and prone to errors. After implementing a cron job with proper logging and error handling, the backups ran automatically every night, freeing up Sarah's time and ensuring data safety.
Best practices & security
File Permissions: Ensure your ETL scripts have appropriate file permissions. They should be executable only by the user running the cron job. Use `chmod 700 your_script.sh` and `chown your_user:your_user your_script.sh` to restrict access. Avoiding Plaintext Secrets: Never store passwords or other sensitive information directly in your scripts. Use environment variables loaded from a secure file (as demonstrated in the advanced example) or consider a dedicated secrets management solution. Remember to restrict access to your environment files using `chmod 600 .env`. Limiting User Privileges: Run cron jobs under the least privileged user account possible. Avoid running them as root unless absolutely necessary. Log Retention: Implement a log rotation policy to prevent your log files from growing indefinitely. Tools like `logrotate` can help with this. Timezone Handling:Be aware of timezone differences between your server and your desired schedule. Use UTC time for cron schedules or explicitly set the `TZ` environment variable in your crontab file to the desired timezone.
Troubleshooting & Common Errors
Cron job not running:
Check cron service status: `sudo systemctl status cron`
Inspect cron logs: `/var/log/syslog` or `/var/log/cron` (depending on your distribution)
Verify script execution permissions: `ls -l your_script.sh` (should be executable for the user running the cron job)
Check for syntax errors in crontab: `crontab -l` (look for any typos or incorrect syntax) Script failing:
Check script logs: Inspect the output of your script to identify any errors or exceptions.
Run the script manually: Try running the script from the command line to reproduce the error and debug it.
Check environment variables: Ensure that all required environment variables are set correctly. Overlapping job executions:
Implement locking: Use a lock file or the `flock` command to prevent multiple instances of the script from running concurrently. Incorrect time/schedule:
Double-check the cron schedule: Verify that the schedule is correct and matches your desired frequency.
Consider TZ: make sure you explicitly set TZ in the crontab file.
Monitoring & Validation
Check job runs: Inspect the cron logs (`/var/log/syslog` or `/var/log/cron`) for entries related to your cron job. You can use `grep` to filter the logs: `grep your_script.sh /var/log/syslog`. Check exit codes: Cron sends email when a job fails. Make sure you have email configured on your server, or redirect the output of the cron job to a file to check the exit code. Logging: Implement comprehensive logging in your ETL scripts to track the progress and status of each execution. Alerting: Set up monitoring and alerting to notify you of any errors or failures in your ETL pipelines. Tools like Nagios, Zabbix, or Prometheus can be used for this purpose.
Alternatives & scaling
While cron is suitable for simple scheduling tasks, it may not be the best choice for more complex or demanding workloads. Here are some alternatives: Systemd Timers: Systemd timers offer more advanced scheduling capabilities compared to cron, including dependency management and event-driven scheduling. Kubernetes Cron Jobs: In a containerized environment, Kubernetes Cron Jobs provide a robust and scalable way to schedule batch jobs. CI Schedulers: CI/CD systems like Jenkins or Git Lab CI can also be used to schedule ETL pipelines, particularly when they are integrated with code deployment processes. Dedicated ETL tools: Airflow, Luigi, and other such tools can be used to define and monitor more complex ETL pipelines.
FAQ
Q: How do I know if my cron job is running?
A: Check the cron logs (usually `/var/log/syslog` or `/var/log/cron`) for entries related to your script. You can also redirect the output of your script to a file and check its contents.
Q: How do I edit my crontab?
A: Use the `crontab -e` command to open the crontab file in a text editor.
Q: How do I remove a cron job?
A: Use the `crontab -e` command to open the crontab file, delete the line corresponding to the cron job you want to remove, and save the file.
Q: What happens if a cron job takes longer to run than the scheduled interval?
A: This can lead to overlapping executions, which can cause problems if the script modifies shared resources. Implement locking mechanisms to prevent this.
Q: How do I run a cron job as a specific user?
A: Edit the crontab for that user using `sudo crontab -u username -e`.
Conclusion
Automating ETL pipelines with cron jobs significantly improves the reliability and efficiency of your data processing. By following the steps outlined in this tutorial, you can confidently schedule and manage your ETL tasks, freeing up valuable time and resources. Remember to test your cron jobs thoroughly and monitor their execution to ensure they are running as expected.
I tested this on Ubuntu 22.04 with `cron` version `3.0pl1-137ubuntu5`.