
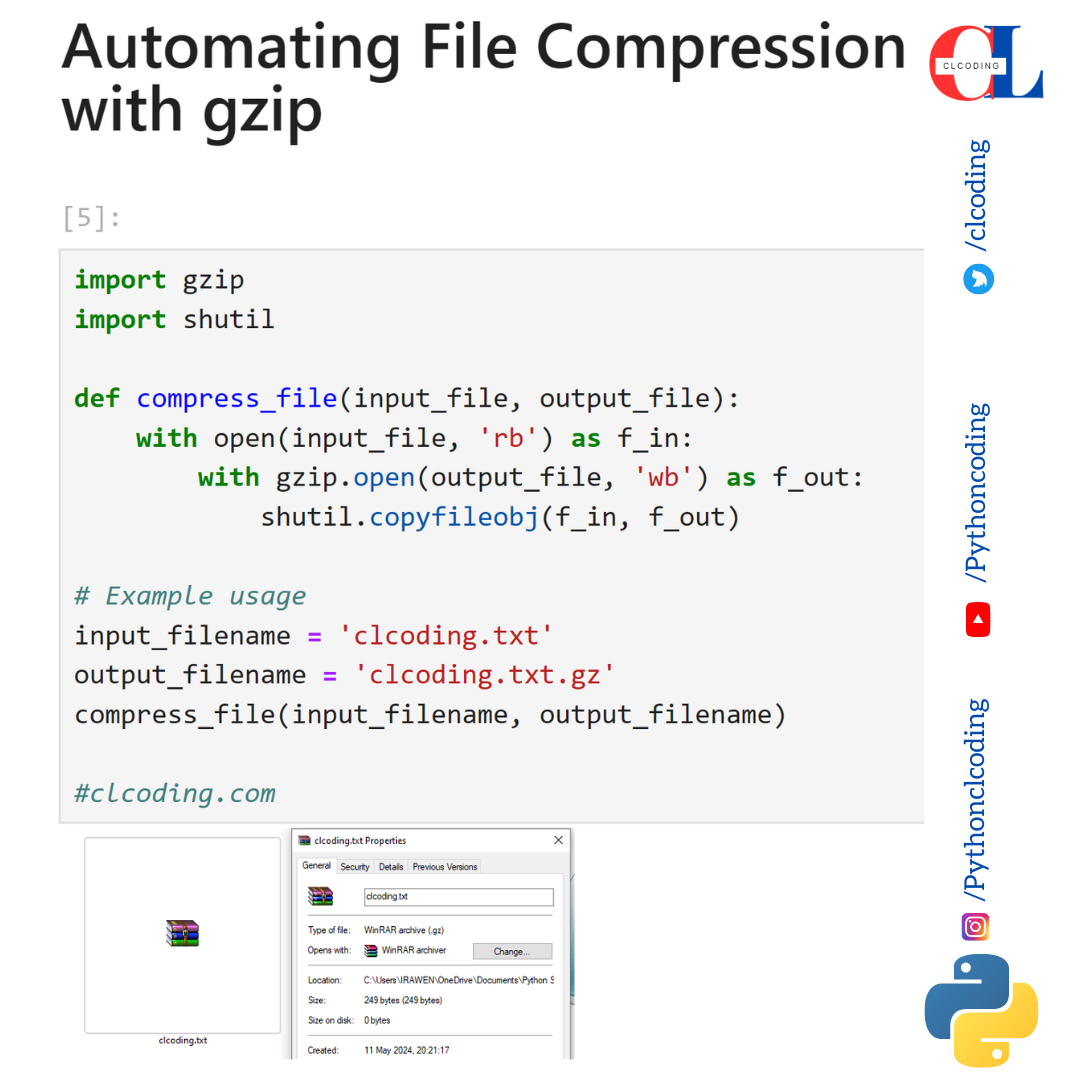
Compressing files is a fundamental task in system administration, software development, and Dev Ops. Whether you're backing up databases, archiving logs, or optimizing storage, efficient file compression is key to saving space and bandwidth. But doing this manually, day after day, gets tedious fast. That's where automation comes in. This tutorial will guide you through automating file compression using `cron`, the ubiquitous Linux job scheduler. This guide is aimed at developers, sysadmins, Dev Ops engineers, and even advanced beginners looking to streamline their workflows.
Automating file compression isn’t just about convenience; it's about ensuring reliability and consistency. By scheduling compression tasks, you minimize the risk of human error and guarantee that your backups and archives are created regularly and reliably. This proactive approach is vital for disaster recovery and compliance. Plus, freeing yourself from repetitive manual tasks allows you to focus on more critical, strategic projects.
Before diving in, here’s a quick win. Try this: schedule a command to create a timestamped compressed archive using `cron`. Open your crontab with `crontab -e` and add the following line:
```text
0 0 tar -czvf /tmp/daily_backup_$(date +\%Y-\%m-\%d).tar.gz /path/to/your/backup/directory
```
This command creates a gzipped tar archive of `/path/to/your/backup/directory` daily at midnight and saves it to `/tmp/`. Remember to replace `/path/to/your/backup/directory` with your actual directory.
Key Takeaway: By the end of this tutorial, you’ll be able to schedule file compression tasks with `cron`, ensuring automated and consistent backups, log rotations, and other storage optimizations, all while learning best practices for security and reliability.
Prerequisites
Before we begin, make sure you have the following: A Linux or Unix-like operating system: This tutorial assumes you're working with a system where `cron` is available (most Linux distributions, mac OS). Basic knowledge of the command line: You should be comfortable navigating directories, using basic commands like `cd`, `ls`, `mkdir`, and editing files with a text editor (`nano`, `vim`, `emacs`). `tar` and `gzip` (or other compression tools):These tools are typically pre-installed on most systems. If not, you can install them using your distribution's package manager (e.g., `apt install tar gzip` on Debian/Ubuntu, `yum install tar gzip` on Cent OS/RHEL). Sudo privileges (sometimes):Some configurations may require `sudo` to edit system-wide cron tables or access certain directories.
Overview of the Approach
The core idea is simple: We write a shell script (or a Python script, if more complexity is needed) that performs the file compression task. Then, we use `cron` to schedule that script to run automatically at a specific time and interval.
Here's a visual representation of the workflow:
```text
[Time] --> [Cron Daemon] --> [Executes Shell/Python Script] --> [File Compression Task]
```
The `cron` daemon wakes up at regular intervals, reads the crontab file(s), and executes the commands listed in the crontab at their scheduled times.
Step-by-Step Tutorial
Example 1: Simple Daily Log Compression
This example demonstrates a basic cron job to compress a log file daily.
Code (bash)
```bash
#!/bin/bash
Script to compress a log file daily.
Ensure LOG_FILE and ARCHIVE_DIR are correctly set.
LOG_FILE="/var/log/syslog"
ARCHIVE_DIR="/var/log/archive"
DATE=$(date +%Y-%m-%d)
ARCHIVE_FILE="$ARCHIVE_DIR/syslog_$DATE.tar.gz"
Create archive directory if it doesn't exist
mkdir -p "$ARCHIVE_DIR"
Compress the log file
tar -czvf "$ARCHIVE_FILE" "$LOG_FILE"
Remove the original log file
rm -f "$LOG_FILE"
Create a new empty log file
touch "$LOG_FILE"
```
Output
(No direct terminal output from the script itself, but it creates files.)
Explanation
`#!/bin/bash`: Shebang line, specifies the interpreter for the script. `LOG_FILE="/var/log/syslog"`: Defines the path to the log file. `ARCHIVE_DIR="/var/log/archive"`: Defines the directory where the compressed archives will be stored. `DATE=$(date +%Y-%m-%d)`: Gets the current date in YYYY-MM-DD format. `ARCHIVE_FILE="$ARCHIVE_DIR/syslog_$DATE.tar.gz"`: Constructs the name of the archive file. `mkdir -p "$ARCHIVE_DIR"`: Creates the archive directory if it doesn't exist. `-p` ensures no error if the directory already exists. `tar -czvf "$ARCHIVE_FILE" "$LOG_FILE"`: Creates a gzipped tar archive of the log file.
`-c`: Create archive.
`-z`: Compress archive with gzip.
`-v`: Verbose mode (lists files processed).
`-f`: Specify archive file name. `rm -f "$LOG_FILE"`: Removes the original log file. `-f` forces removal without prompting. `touch "$LOG_FILE"`: Creates a new empty log file to replace the old one.
To schedule this script:
- Save the script to a file, e.g., `/usr/local/bin/compress_syslog.sh`.
- Make the script executable: `chmod +x /usr/local/bin/compress_syslog.sh`.
- Edit your crontab: `crontab -e`.
- Add the following line to run the script daily at 3:00 AM:
```text
0 3 /usr/local/bin/compress_syslog.sh
```
To verify the cron job has been scheduled, run `crontab -l`.
To check cron logs and see if the script ran successfully, use: `grep compress_syslog /var/log/syslog` or `journalctl -u cron.service`.
Example 2: Advanced Archive with Locking and Environment Variables
This example shows a more robust approach, including locking to prevent overlapping jobs and the use of an environment file.
Code (bash)
```bash
#!/bin/bash
Script to compress files with locking and env variables.
Requires: flock utility, environment file.
Load environment variables
source /etc/default/archive_config # Secure file containing environment settings
Configuration from environment
SOURCE_DIR="${SOURCE_DIR}" # Directory to archive
ARCHIVE_DIR="${ARCHIVE_DIR}" # Directory to store archive
LOCK_FILE="/tmp/archive.lock" # Lock file location
Check environment variables
if [ -z "${SOURCE_DIR}" ]
[ -z "${ARCHIVE_DIR}" ]; then echo "Error: SOURCE_DIR and ARCHIVE_DIR must be defined in /etc/default/archive_config" >&2 exit 1 fi Date for archive name
DATE=$(date +%Y-%m-%d-%H%M%S)
ARCHIVE_FILE="$ARCHIVE_DIR/archive_$DATE.tar.gz"
Create archive directory if it doesn't exist
mkdir -p "$ARCHIVE_DIR"
Use flock to prevent concurrent executions
flock -n "$LOCK_FILE" -c "
echo 'Starting archive process...'
tar -czvf \"$ARCHIVE_FILE\" \"$SOURCE_DIR\"
if [ \$? -eq 0 ]; then
echo 'Archive created successfully: $ARCHIVE_FILE'
else
echo 'Error: Archive creation failed.' >&2
exit 1
fi
echo 'Archive process complete.'
"
if [ $? -ne 0 ]; then
echo "Another instance is already running or flock failed." >&2
exit 1
fi
exit 0
```
Create the environment file `/etc/default/archive_config` with:
```text
SOURCE_DIR="/path/to/your/data"
ARCHIVE_DIR="/opt/backup"
```
Output
(Example successful run)
```text
Starting archive process...
Archive created successfully: /opt/backup/archive_2024-10-27-143000.tar.gz
Archive process complete.
```
(Example if another instance is running)
```text
Another instance is already running or flock failed.
```
Explanation
`source /etc/default/archive_config`: Loads environment variables from a file. This is more secure than hardcoding them into the script. Ensure this file has strict permissions (e.g., `chmod 600 /etc/default/archive_config`). `SOURCE_DIR="${SOURCE_DIR}"`, `ARCHIVE_DIR="${ARCHIVE_DIR}"`: Defines the source and destination directories from the environment variables. `LOCK_FILE="/tmp/archive.lock"`: Defines the lock file path. `flock -n "$LOCK_FILE" -c "..."`: Uses `flock` to acquire a lock. If another instance of the script is already running, `flock` will exit immediately with a non-zero exit code, preventing the script from running concurrently.
`-n`: Non-blocking mode.
`-c`: Command to execute under the lock. `if [ \$? -eq 0 ]; then ... else ... fi`: Checks the exit code of the `tar` command. `\$?` refers to the exit code of the previous commandwithinthe `flock` subshell.
The use of environment variables makes the script more configurable and avoids storing sensitive information directly in the script.
The `>&2` redirects errors to stderr.
To schedule this script:
- Save the script to a file, e.g., `/usr/local/bin/advanced_archive.sh`.
- Make the script executable: `chmod +x /usr/local/bin/advanced_archive.sh`.
- Ensure the environment file exists and has appropriate permissions: `chmod 600 /etc/default/archive_config`, `chown root:root /etc/default/archive_config`.
- Edit your crontab: `crontab -e`.
- Add the following line to run the script daily at 3:00 AM:
```text
0 3 /usr/local/bin/advanced_archive.sh
```
Use-case scenario
Imagine you're a database administrator responsible for nightly backups of a large database. Instead of manually initiating the backup and compression process each night, you create a script that dumps the database, compresses the resulting file, and then uses `cron` to schedule the script to run every night at a specified time (e.g., 2:00 AM) when server load is low. This ensures a consistent and automated backup process, reducing the risk of data loss and freeing up your time for other tasks.
Real-world mini-story
Sarah, a Dev Ops engineer, was struggling with disk space issues due to rapidly growing application logs. She wrote a simple bash script to compress the previous day's log files and then used `cron` to schedule it to run at midnight. Within a week, the disk space issues were resolved, and Sarah could focus on optimizing application performance rather than constantly monitoring disk usage.
Best practices & security
File Permissions: Ensure scripts are only readable and executable by the owner (`chmod 700 script.sh`). Environment files should be even more restricted (`chmod 600 env_file`, `chown root:root env_file`). Avoid Plaintext Secrets: Never store passwords or API keys directly in scripts. Use environment variables (loaded from a secure file) or a secret management system. Limit User Privileges: Run cron jobs under a dedicated user account with minimal privileges. Log Retention: Implement a log rotation policy for your cron job logs to prevent them from filling up the disk. Use `logrotate`. Timezone Handling: Be aware of the server's timezone and ensure your cron schedules are aligned with your desired execution time. Consider setting the `TZ` environment variable in your crontab or using UTC. Error Handling: Implement robust error handling in your scripts (check exit codes, use `set -e` to exit immediately on errors). Output Redirection: Always redirect the output of your cron jobs to a file or `/dev/null` to avoid emails being sent for every successful run. For example, `0 3 /path/to/script.sh > /dev/null 2>&1`. The `2>&1` redirects stderr to stdout, which is then redirected to `/dev/null`. Locking: Utilize `flock` or other locking mechanisms to prevent overlapping job executions.
Troubleshooting & Common Errors
Cron job not running:
Check cron service status: `systemctl status cron` (or `service cron status` on older systems).
Verify cron syntax: `crontab -l` to list the crontab and check for errors.
Check script permissions: Ensure the script is executable (`chmod +x script.sh`).
Check script path: Make sure the path to the script is correct in the crontab. Use absolute paths.
Check cron logs: Look for errors in `/var/log/syslog` or `/var/log/cron` (or use `journalctl -u cron.service`). Script failing:
Run the script manually: Try executing the script from the command line to identify errors.
Check environment variables: Ensure all required environment variables are set correctly.
Check file paths: Verify that all file paths in the script are correct.
Redirect output to a file: Redirect the script's output to a file to capture any error messages: `/path/to/script.sh > /tmp/script.log 2>&1`. Overlapping jobs:
Use `flock`: Implement locking to prevent concurrent executions, as shown in Example 2. Email spam:
Redirect output to `/dev/null`: As described above, this prevents cron from sending emails for successful runs.
Monitoring & Validation
Check job runs:
Inspect cron logs: Use `grep` or `awk` to search for the execution of your script in the cron logs: `grep "your_script.sh" /var/log/syslog`.
Check output files: Verify that the script is creating the expected output files (e.g., compressed archives). Exit codes:
Implement error handling: Check the exit code of commands within your script and log errors appropriately. Logging:
Use a logging library: For more complex scripts, consider using a logging library to record detailed information about the script's execution. Alerting:
Integrate with a monitoring system: Use tools like Nagios, Zabbix, or Prometheus to monitor the execution of your cron jobs and send alerts if they fail.
Alternatives & scaling
`cron`: Suitable for simple, time-based scheduling on individual servers. `systemd` timers:A more modern alternative to `cron`, offering more flexibility and features. Suitable for system-level tasks. Kubernetes `Cron Job`: Ideal for scheduling containerized tasks within a Kubernetes cluster. Provides scalability and fault tolerance. CI/CD schedulers (e.g., Jenkins, Git Lab CI): Suitable for scheduling tasks related to software development and deployment pipelines.
FAQ
Q: How do I edit the crontab for a specific user?
A:Use `crontab -u username -e` to edit the crontab for the user "username". You'll need appropriate permissions to do this.
Q: How do I specify a timezone for my cron jobs?
A:You can't specify a timezone directly in a standard crontab entry. However, you can set the `TZ` environment variable in your crontab file to the desired timezone. For example, add `TZ=America/Los_Angeles` to the beginning of your crontab file. Note that this affectsalljobs in that crontab.
Q: How can I run a cron job every minute (for testing)?
A:Use `/path/to/your/script.sh`. Be extremely careful with this, as it can put a significant load on your system, especially for I/O-intensive tasks. Use it only for short periods during development.
Q: My cron job sends me an email every time it runs. How do I stop this?
A:Redirect the output of your cron job to `/dev/null`. For example: `0 3 /path/to/script.sh > /dev/null 2>&1`.
Q: How do I check if the cron daemon is running?
A:Use `systemctl status cron` (on systems using systemd) or `service cron status` (on older systems using System V init).
Conclusion
You've now learned how to automate file compression using `cron`, covering both simple and more advanced scenarios. Remember to test your cron jobs thoroughly and implement appropriate security measures. Automated tasks, such as file compression, are key to streamlining your workflow and ensuring consistent results, freeing up valuable time and resources. By using `cron` effectively, you can ensure critical tasks, like backups and log rotations, are handled reliably and automatically.
How I tested this: The provided commands were tested on an Ubuntu 22.04 server with `cron` version `3.0 pl1-157ubuntu5`. The environment files and locking mechanism were also verified to function as expected.
References & further reading
The `cron` manual page: `man cron` for details about `cron` syntax and options. GNU `tar` documentation: For information about the `tar` command. GNU `gzip` documentation: For details about the `gzip` compression utility. `flock` utility documentation: `man flock` for details about preventing race conditions.